
Anvil Transactions
So, you want to know more about Anvil transactions? Fantastic!
Anvil's transaction system provides two basic facilities:
- Updating multiple small files atomically (a "transaction")
- Ensuring that specified updates to large files are written entirely before a transaction is committed
Notice that this notion of "transactions" is not the same as the higher-level transactions you might build on top of it, for example the SQL transactions supported by SQLite (as available in our version of SQLite modified to use Anvil). Anvil transactions are strictly ordered, and at most one can be active at a time, similar to ext3 transactions.
There are actually two implementations of the transaction system in Anvil: one that uses the explicit dependency specification API provided by Featherstitch patchgroups, and one that counts on the implicit write-ordering semantics of Linux ext3 in ordered mode. The Featherstitch version was much easier to write correctly, but the ext3 version allows many more machines to run Anvil. (It would be nice if interfaces like Featherstitch patchgroups eventually became available in Linux, allowing software like Anvil's transaction layer to be implemented more easily.)
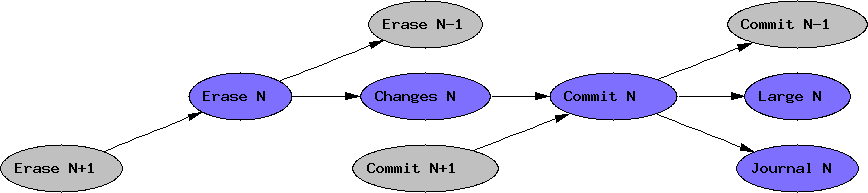
Each transaction basically has four parts that must occur in order:
- Write a journal of the changes to be made
- Write a commit record committing those changes
- Write the changes themselves
- Erase the commit record
A diagram is in order here. Here is what we want:
To see how we use ext3 to build Anvil transactions, first we'll give a quick review of how ext3 works. As previously mentioned, its transactions are actually fairly similar to Anvil's: they are strictly ordered, and consist of the same four basic pieces. The changes that are written to the journal are only file system metadata - updates to inodes, block bitmaps, and directory data. Everything else (basically, normal file data) is treated just like Anvil transactions treat the specified large file updates: it must be written before the transaction commits. (This was originally seen as a security feature, in that it prevents a transaction from causing files to refer to reallocated blocks without ensuring that the old blocks have been erased first. It has the side effect of making fsync() potentially very slow and has been the subject of much debate recently.)
The "trick" we use is based on the following observation about ext3 in this mode: writing to a file and then renaming it will force all the writes to be committed before the rename, without forcing the writes to go to disk immediately. This is because the writes will be "normal file data" that must be written before the current transaction commits, and the rename, as a modification to directory data, will be part of that transaction. Well, actually, the writes might end up spread over several transactions, and the rename might be in a later transaction, but since transactions are strictly ordered the relative ordering will still be correct.
So how do we build the transaction system using this fact? Basically, we create a log file for the small file updates, and rename it for each transaction. During the transaction, the rest of Anvil uses the transaction API to read and write the small files. Writes are buffered in the application, rather than being written out to the actual files. At the end of the transaction, the buffered updates are appended to the log, and the log file is renamed. The rename becomes the commit record: the name itself contains a number indicating how much of the log file has been committed (i.e. the size of the file, as of the rename).
So now the Anvil transaction is committed, and we can write to the actual files, right? Turns out, not quite. Remember the ext3 "guarantee": all the file writes made during an ext3 transaction will be written to disk before any of the file system metadata is committed as part of that transaction. If we were to write the small files now, there would be a very good chance that those writes would actually be forced to occur before the rename that committed them.
To make sure that doesn't happen, we have to do one of two things: either wait for (or force) the ext3 transaction to end, or make the small file updates count as file system metadata. The former solution is really inefficient, so we have to do the latter. Fortunately this is easy: we write new copies of the small files, and rename them on top of the originals. The data in the new copies will probably still be written before the commit, but the renames will be correctly ordered.
The transaction library also needs to provide a means to write large file data so that it will be written to disk before the current Anvil transaction commits. Fortunately this is actually quite easy - in fact it is automatic when using ext3. Simply writing to any file will have this effect. Nevertheless, we provide (and use) an API to request this behavior, anticipating that other systems (for instance Featherstitch) may require some additional work to accomplish it.
These mechanisms all work well for relatively few updates to relatively small files: we won't use that much memory buffering updates, and the log file and new copies of the small files will not use much space on disk or create too much I/O work. But how then do we write larger amounts of data transactionally?
Enter the system journal. The system journal is built using the transaction system. It consists of two files: a small metadata file, updated transactionally using the transaction system, and a larger file, containing most of the data. The metadata file contains a pointer into the system journal, indicating how much of it is valid. (This is very similar to how the transaction log uses its file name to keep track of how much of it is valid. The reason we don't just do that is that the system journal's metadata might need to be updated atomically with other such small metadata files, and a rename won't guarantee that.)
We append data to the system journal throughout the transaction, allowing the file system to start writing it to disk whenever it is convenient. Since the metadata file points earlier than the appended data, that data will be ignored if we crash without committing it. At the end of the transaction, we just update the metadata to include the appended data. The large writes are guaranteed to hit the disk before the metadata commits, ensuring everything is consistent.
The system journal also provides mechanisms to multiplex log records from multiple sources together, and demultiplex them during recovery. Each source acquires a unique ID from the system journal (tracked in the system journal's metadata file), and uses it when appending its log entries to the system journal. When that source no longer needs its log entries (perhaps because the data has been written elsewhere in a read-optimized order), it can relinquish its ID, allowing the system journal to recover the space used for its log entries. This is accomplished by periodically scanning the log and copying only the live entries to a new log file, and then deleting the original log file. Since this can be expensive, the system journal also implements an optimization: if the number of live log entries reaches zero, the log can be deleted without the scan. This tends to happen in practice, since entire batches of log records "die" together when system journal IDs are relinquished.